Strong vs Weak Selectivity – Everything A DBA Needs To Know
Previous post I introduced you to Selectivity and Cardinality, and asked a question at the end.
Thanks to all the readers that responded! You are awesome!
To refresh your memory and put you in the mindset for today’s post:
Selectivity = Number Of Rows Returned / Total Number Of Rows
Cardinality = Number Of Rows Returned = Selectivity * Total Number Of Rows
Last week’s question was:
What do you think is more important for the optimizer to know, the selectivity (1% of the data is returned) or cardinality (1000 rows returned)?
And the winner is … drum-roll please… selectivity!!! Yay!
1.What Does A DBA Needs To Know About Selectivity?
2.What Is Weak Selectivity?
3.What Is Strong Selectivity?
4.Why Is This Important For DBAs?
What Does A DBA Needs To Know About Selectivity?
When the optimizer generates an execution plan, it chooses the data access operations, ie. full table scan, index access or others.
These access operations, can be classified into 2 groups:
- operations with weak selectivity
- operations with strong selectivity
To really confuse you, the weak selectivity is also referred to as high selectivity, and the strong selectivity is also referred to as low selectivity.
Let me explain this to you in simple words, so no confusion in the future.
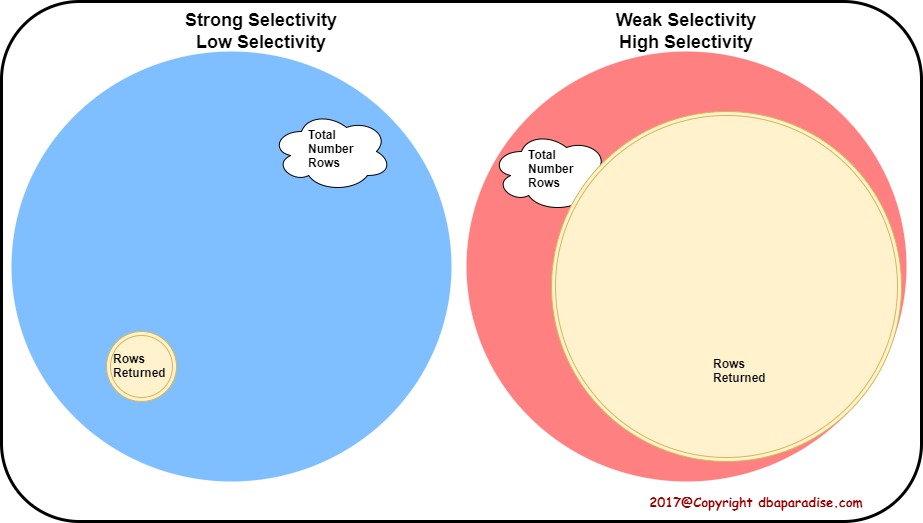
What Is Weak Selectivity?
When a data access operation is classified as an operation with weak selectivity, it basically means it returns a large amount of rows, compared to the total number of rows.
ie. selectivity = 90% or 0.9
Weak selectivity is also called high selectivity, because the number itself is close to 100% or 1. Now you understand why the two terminologies.
What Is Strong Selectivity?
When a data access operation is classified as an operation with strong selectivity, it means it returns a small amount of rows, compared to the total number of rows.
ie. selectivity = 0.5% or 0.05
Strong selectivity is also called low selectivity, because the number itself is close to 0% or 0.
Why Is This Important For DBAs (Weak and Strong Selectivity)?
I don’t like to learn things for the sake of learning. I like to understand why do I need to know it, and how it can help me in my day to day job.
It is good to have at least a basic understanding about selectivity, in order to be able to have an opinion on the access path that the optimizer chose when generating the execution plan.
A DBA wants to be able to answer the following questions when reading an execution plan:
Was this a good way to access the data?
or
What should the access path be in order to have a good execution plan?
let me back out a bit.
Strong or weak selectivity matters to the optimizer because accessing the data in a way that works well with weak selectivity, could work bad for strong selectivity.
An example makes it easier to understand:
select * from employees; -- 1,000 rows returned. select * from employees where country='CAN'; -- 900 rows returned. selectivity = number of rows returned/total number of rows = 900/1000 = 0.9 or 90%
It is safe to say that selectivity is weak (it returns most of the data from the table) or that selectivity is high.
In this case, it would be a bad access path to get the data by using an index. Most likely the best way to access the data would be by reading the whole table.
To finalize this idea, lets look further at another example.
select * from employees where country='RO'; -- 2 rows returned. selectivity = number of rows returned/total number of rows = 2/1000 = 0.002 or 0.2%
Selectivity is very strong (it returns a small fraction of the data) or selectivity is low as a number.
In this case, it would be a bad access path to access the data by using a full table scan. Most likely the best way to access the data would be by an index.
We can only be certain of weak and strong selectivity for numbers close to 0 and 1 (the ends of the interval). In between is more of a gray area.
Remember this, if nothing else, that for the optimizer, the number of rows returned or accessed (cardinality) is not relevant when choosing an access path. The selectivity is!
Let me finish with a nice illustration! Feel free to print it!
If you enjoyed this article, and would like to learn more about databases, please sign up below, and you will receive
The Ultimate 3 Step Guide To Find The Root Cause Of The Slow Running SQL!
–Diana
Hi
Dear,
can not we take a bakup of datafile using expdp y??
can t we take a backup of shcema using rman ?? yy
Hi Sai,
This comment is not really relevant to the article. You can always email me with questions.
To answer your questions: you cannot take a backup of a datafile with expdp. Expdp utility is for exporting the data from the database.
You can’t really take an rman backup of a schema. RMAN is used to backup the database (datafile).
Remember: rman – backup datafile/tablespace; expdp – backup schema
Hope this helps.
Diana
ThankQ Dianarobete…………….
Hello,
How does an index impacts the inserts and updates when the selectivity is low?
Thank you!
Hi Adriana,
when you say selectivity is low, I think you mean weak, ie. lots of rows are returned compared to the total number of rows.
Any index on a table will impact the DML on that table, as the index has to be maintained during the DML operations (whether or not the selectivity is strong or weak).
The more indexes you have, the more work does the database need to perform for DML statements.
I don’t have an example setup for this, but you could probably test it out. Hope this answers your questions!
Cheers!