
5 Steps To Automate Listen.log Mining
If you read last week’s article, then you most likely understand the importance and the benefit of reviewing the listener.log files in your environment regularly.
Have you thought about implementing the process? Do you find it scary and too complicated?
To tell you the truth, if the process is not automated, then chances are you are not going to review anything. The bigger the environment you work in, the more files are there to review.
I built the process, around Arup Nanda’s article and method. I haven’t changed much in what he does, instead I introduced more automation to it. Have you read his article? Here is a link to it!
Today I’ll show you the process I have setup, that reads ALL the listener.log files, for ALL your listeners in your enterprise, sends you a report with all the errors from the previous day, and generates a report with all the connections, a report that you can keep forever, for upgrade, or for audit purposes.
There are multiple steps in this process, I’ll discuss them in detail below.
1. Determine What You Need.
From an infrastructure point of view, to be able to setup this process, these are the things you need:
- a database that will hold the external tables for the listener log files. There will be multiple external tables, one for each listener.
A good database for this would be the DBA’s database (dbatools), or the Cloud Control repository, or the rman catalog, but really any database will do. - a schema owner of the external tables, let’s call this: LIST_REP
- directory object, external tables, mining function. There will be one external table for each listener.log file
- a central location to copy the listener.log files, a location that is accessible by the repository database. This is the location where the directory object points to.
2. Keep The Listener Log Small.
For this whole process to work, I’d like to make sure the listener.log files only holds one day worth of data. That is why I have a job that runs every night at 23:59 and cycles the listener.log to a file listener.log.date, ie listener.log.1 for Monday.
I keep 7 days worth of logs. You could setup a different strategy for this, but what is important to take away from here is, that the listener.log should only have one day worth of data in it.
This job needs to run on each server that has a listener. Let’s name this script: recycle_listener_log.sh
3. Copy The Listener Log To Central Location.
Each of the listener.log files that you recycled in the previous step, needs to be copied to a central location. You need to come up with a naming convention for these copied files.
The naming convention I like to use is listener.ora.servername, as in listener.ora.prod01. This naming convention makes it very clear the source location of the listener log file.
In the central location for your logs, you could end up with many files, for our example, see below:
listener.ora.test01
listener.ora.test02
listener.ora.prod01
listener.ora.prod02
This copy is performed by another script, let’s call it copy_listener_log.sh. This script must run on each server that runs a listener.
4. Setup The LIST_REP Schema And Objects.
I recommend creating a dedicated schema for all the objects involved in this process. Let’s call this schema LIST_REP.
This schema will own the directory object, external tables, mining function, basically all the objects that Arup Nanda is recommending in his article.
There will be an external table for each listener log file. For our example, we will have the following tables: LISTENER_TEST01, LISTENER_TEST02, LISTENER_PROD01, LISTENER_PROD02.
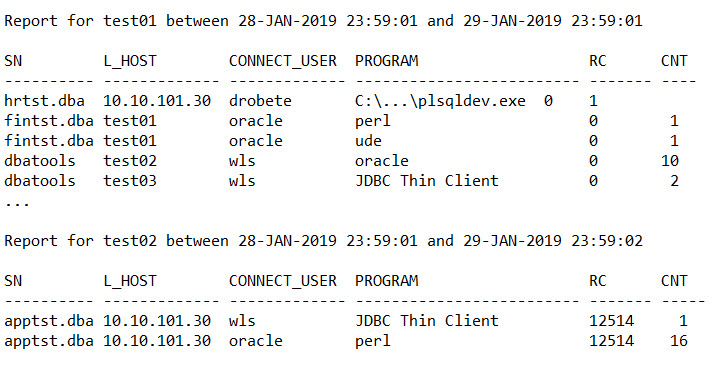
5. Create The Reporting Scripts.
I created two scripts, one that sends me an email every morning with only the TNS errors from the listener.log file. This email is nice and short, and I can review it daily.
The other script generates a report with all the connections to the database that are going through the listener. This report is saved on the server, and kept indefinitely, as you never know when you will need it.
Let’s call these scripts: listener_report_all.sh and listener_report_error.sh
Below is a sample output of the reports:
If you enjoyed this article, and would like to learn more about databases, please sign up below, and you will receive
The Ultimate 3 Step Guide To Find The Root Cause Of The Slow Running SQL!
–Diana
Good article
I think use ElasticSearch for such kind of tasks also fits good