
3 Things You Must Know About Oracle Optimizer Statistics
You keep hearing that statistics are important for the Oracle database.
You keep hearing that you should collect statistics.
A DBA tells you that you should gather incremental stats and extended stats.
Another DBA tells you that histograms are “The Thing”.
You feel confused, you don’t know what to do, and how to do it, AND you do nothing.
Does this sound familiar?
DBAs know what statistics are, or at least we pretend we do, but do we really know?
Can we explain to a non DBA user what Oracle optimizer statistics are and why they are important, without that person looking at you and saying “Huh?”
If you need a refresher on optimizer statistics, then this post is for you!
If you have no knowledge or very little knowledge on optimizer statistics, then this post is for you!
If you know it ALL, I’d love to hear from you! Leave a comment below!
I’ll have a series of post on Optimizer Stats in the coming weeks, but first, let’s start with the basics!
Remember, you can’t build knowledge if the basics are missing. Just as you can’t multiply numbers if you don’t know how to add numbers!
1.What Are Optimizer Statistics In Oracle?
2.What Type Of Statistics Can I Gather?
3.What Is The Purpose Of Optimizer Stats?
1.What Are Optimizer Statistics In Oracle?
In order for the database to come up with a good execution plan, the Cost Based Optimizer (CBO) needs to have optimizer statistics available.
The optimizer statistics are collections of information about the objects, mostly tables and indexes, that exist in the database, and information about the system as a whole.
The stats are stored in the data dictionary and are available in the data dictionary views, such as DBA_TABLES, DBA_INDEXES, DBA_TAB_STATISTICS and others.
2.What Type Of Statistics Can I Gather?
Optimizer stats sounds like a big box of surprises! Have you ever wondered what is in it? What is it made up of?
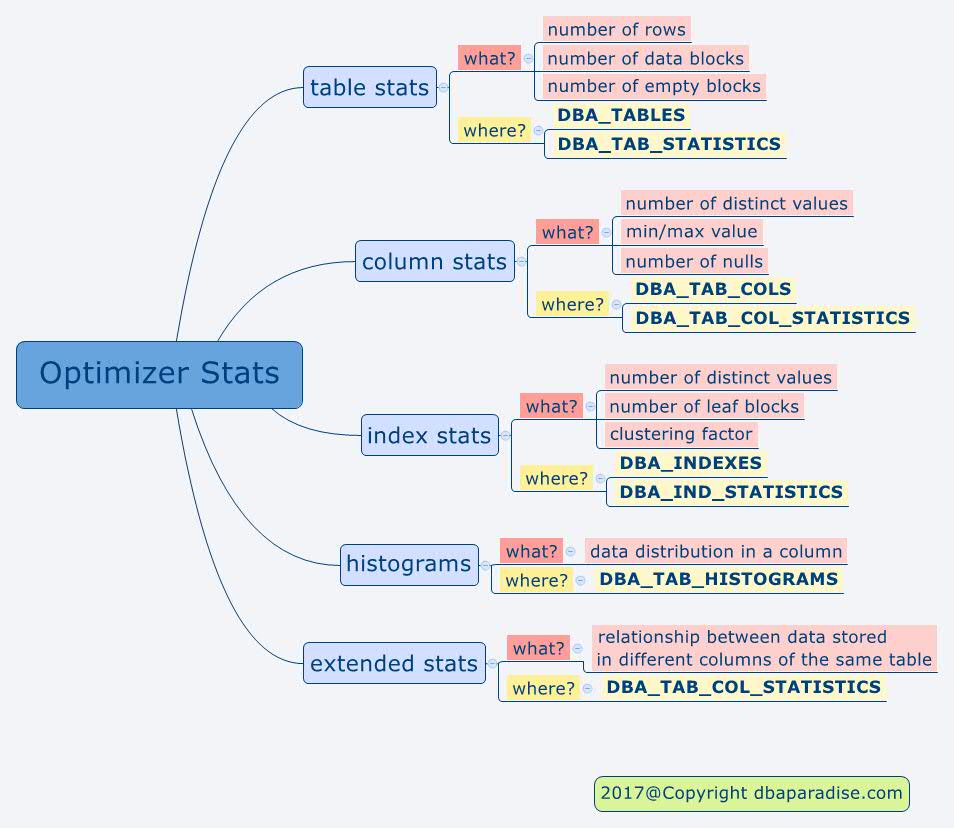
- Table Statistics
– represent information about the table, such as number of rows in the table, number of data blocks used by the table, number of empty blocks.
– these statistics are accurate at the time they were gathered. The stats do not get automatically updated as the table is updated, unless new stats are gathered again. You have table A with 1000 rows. You gather stats on the table (num_rows = 1000). If you insert another 1000 rows (in reality you have 2000 rows in the table), the statistics will still show 1000, until you gather new stats.
– to see information about the table stats, check out DBA_TAB_STATISTICS, DBA_TABLES, DBA_SEGMENTS. You will see columns such as: num_rows, blocks, empty_blocks,avg_space, avg_row_len and others. These are optimizer statistics on the table. If these columns are NULL, that means the table has no stats. - Column statistics
– these are statistics related to the data stored in the column. The stats are made up of information such as number of distinct values, minimum and maximum value stored in the column, number of null values.
– to check out the column stats for a table, see DBA_TAB_COL_STATISTICS, DBA_TAB_COLS. You will see columns such as: num_distinct, low_value, high_value, density, num_nulls, and others. - Index Statistics
– these stats contain information about the index itself. Information such as number of distinct values in the index, number of leaf blocks, the clustering factor. You might not know what clustering factor or leaf block is, and that is totally fine. These thing will be the topic of a future post.
– to see information about index stats, check out DBA_IND_STATISTICS, DBA_INDEXES. Look at columns such as blevel, leaf_blocks, distinct_keys. If these columns are NULL, that means the index has no stats. - Histograms
– are additional statistics about the data distribution for a column. By default, the optimizer thinks the rows are distributed evenly across the distinct values in a column.Lets say table A has a 100 rows. There is a column called: colour, with 2 distinct values: red and blue. Without histograms, the optimizer will think there are 50 rows that are red, and 50 rows that are blue. Is this true?
What if there are 2 rows that are red, and 98 rows that are blue. Without histograms, the optimizer would not know this information. When the distribution is not uniform, the data is skewed.
In order to correctly represent a non-uniform data distribution, a histogram is required on the column.
Oracle determines automatically the columns that require histograms, by looking at the column usage in SYS.COL_USAGE$ view.Where can you see histogram information? Check DBA_TAB_COLS, the column HISTOGRAM will tell you if there are histograms gathered on that column. For detailed information check out DBA_TAB_HISTOGRAMS
- Extended Statistics
– are additional information about the relationship between data stored in different columns of the same table.
Usually this data is meaningful in business terms. By default there is no way for the optimizer to know the relationship of the data between column A and B.Imagine you have a table called CARS, with columns MAKE and MODEL. There is a relationship between the make and model columns. Matrix (model) can only be a Toyota (make).
The optimizer would not know that, unless you gather extended statistics on the group of columns.
3.What Is The Purpose Of Optimizer Stats?
I kept telling you what the stats are, but did not really revealed the use for them. Why does the optimizer need these stats?
The simple answer is: to generate a good execution plan!
The more detailed answer is below.
When the optimizer is generating an execution plan, it uses the table and column statistics to determine the number of rows returned by an operation (cardinality). The optimizer needs to determine if a full table scan or an index scan would be better. If it’s an index scan, should that be a full index scan, an index range scan, or an index skip scan. There are so many questions and possibilities for the optimizer.
The estimates the optimizer provides can be as accurate as the stats on the tables, columns, and indexes.
4. Bonus – Putting It All Together!
As always, I put together a visual reminder of all the things we discussed today! Feel free to print it!
If you enjoyed this article, and would like to learn more about databases, please sign up below, and you will receive
The Ultimate 3 Step Guide To Find The Root Cause Of The Slow Running SQL!
–Diana
Hi,
Excellent Article. Now, I wish to see a relation of all this with the new Database 18c “self tuning” announced by our “uncle Larry” ! What will change? Do you think all this still will be necessary to worry about it?
Hi Alexandre,
I believe this information is still relevant and will be for many years to come. The reason I believe this is, when 18c comes out, or 19 or any future release, not everyone will upgrade right away. As of this writing, I am still managing 10g databases, and there are companies that are still running 9i. Should a DBA spend time learning about stats, and be good at it? Absolutely!
How 18c will behave with the stats…will see once people start using it.
Hope this helps!
Diana
Thanks for the refresh
Diana,
Just word “Wow” !!! The way you explained with examples in simple term is really excelllent!!.
Keep going dude!!.
Thanks
-Yousuf
Thanks for the excellent explanation.